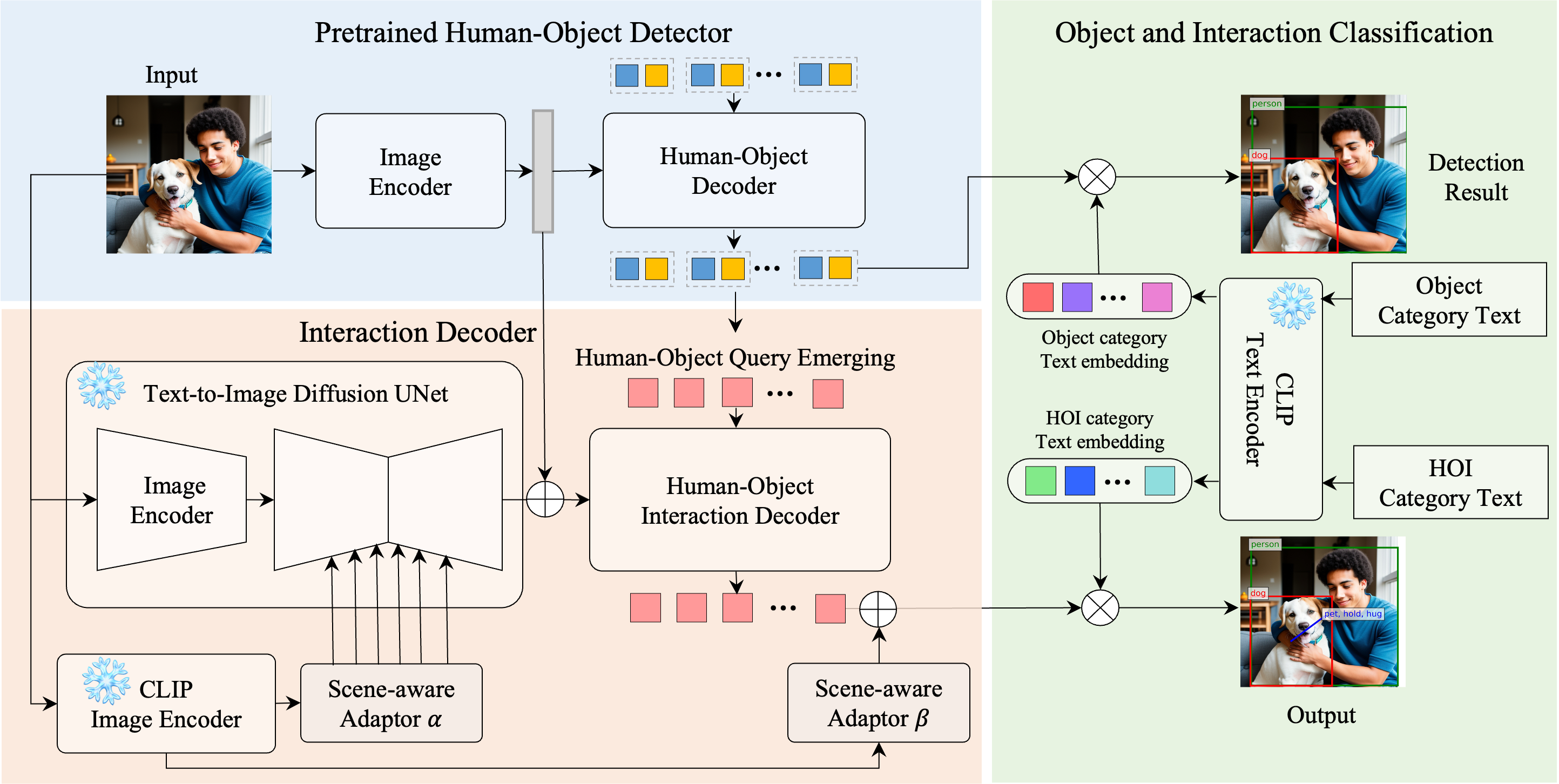
Overview of DiffHOI, comprising a pretrained human-object decoder, a novel interaction decoder, and CLIP-based object and interaction classifiers.
New SOTA
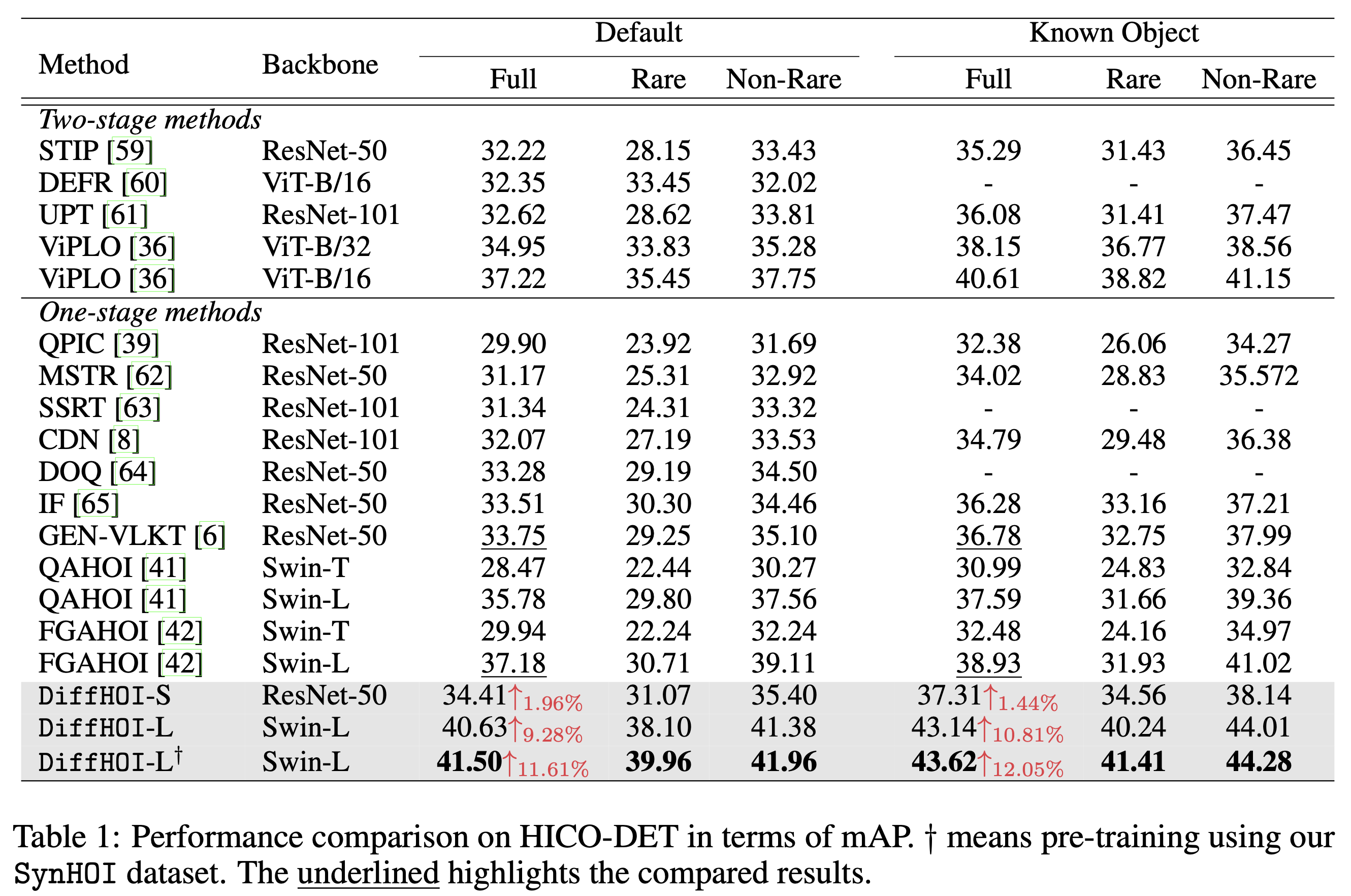
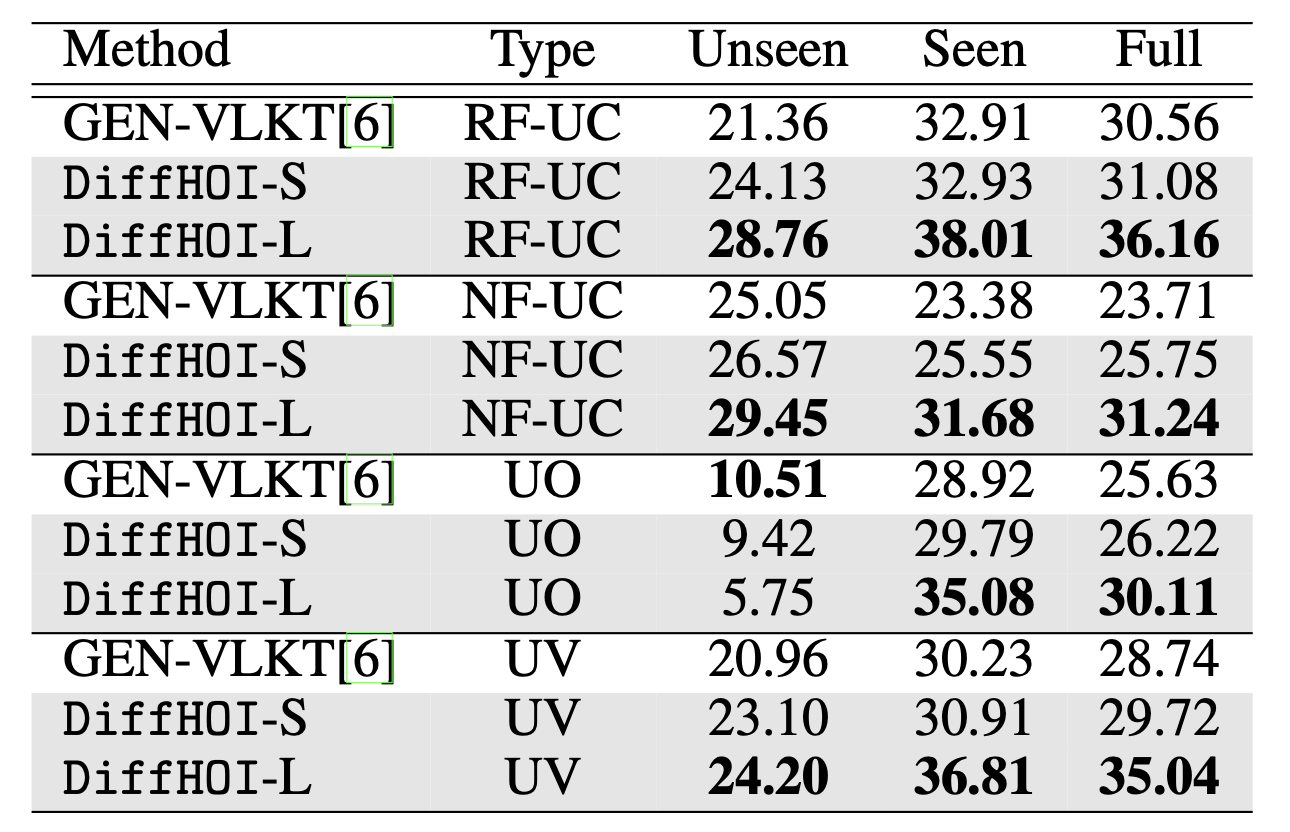
This paper investigates the problem of the current HOI detection methods and introduces DiffHOI, a novel HOI detection scheme grounded on a pre-trained text-image diffusion model, which enhances the detector's performance via improved data diversity and HOI representation. We demonstrate that the internal representation space of a frozen text-to-image diffusion model is highly relevant to verb concepts and their corresponding context. Accordingly, we propose an adapter-style tuning method to extract the various semantic associated representation from a frozen diffusion model and CLIP model to enhance the human and object representations from the pre-trained detector, further reducing the ambiguity in interaction prediction. Moreover, to fill in the gaps of HOI datasets, we propose SynHOI, a class-balance, large-scale, and high-diversity synthetic dataset containing over 140K HOI images with fully triplet annotations. It is built using an automatic and scalable pipeline designed to scale up the generation of diverse and high-precision HOI-annotated data. SynHOI could effectively relieve the long-tail issue in existing datasets and facilitate learning interaction representations. Extensive experiments demonstrate that DiffHOI significantly outperforms the state-of-the-art in regular detection (i.e., 41.50 mAP) and zero-shot detection. Furthermore, SynHOI can improve the performance of model-agnostic and backbone-agnostic HOI detection, particularly exhibiting an outstanding 11.55% mAP improvement in rare classes.

Large-scale. SynHOI consists of 146, 772 images, 157, 358 person bounding boxes, 165,
423 object bounding boxes, and 282, 140 HOI triplet instances. It provides approximately four times
the
amount of training data compared to HICO-DET.
Class-balance. SynHOI can effectively address the long-tail issue in previous
datasets,
where 343 HOI categories have fewer than 50 images in HICO-DET. Combining SynHOI with HICO-DET reduces
the number of HOI categories with fewer than 50 images to only three.
High-diversity. SynHOI exhibits a high level of diversity, offering a wide range of
visually dis- tinct images.
High-quality. SynHOI showcases high-quality HOI annotations. First, we employ
CLIPScore
to measure the similarity between the synthetic images and the corresponding HOI triplet prompts.
The SynHOI dataset achieves a high CLIPScore of 0.805, indicating a faithful reflection of the HOI
triplet information in the synthetic images.

@article{yang2023boosting,
title={Boosting Human-Object Interaction Detection with Text-to-Image Diffusion Model},
author={Yang, Jie and Li, Bingliang and Yang, Fengyu and Zeng, Ailing and Zhang, Lei and Zhang, Ruimao},
journal={arXiv preprint arXiv:2305.12252},
year={2023}
}